
Express 서버 다운 이슈: 백엔드-프론트엔드 통신 지연
[01] 시스템 환경
이슈가 발생한 시스템은 백엔드와 프론트엔드 프로젝트는 별도로 구성되어 있다.
- 웹 어플리케이션 서버(WAS): Java, Spring Boot
- 웹 서버(WEB): JavaScript, React, Express
- 클라우드 인프라: GCP
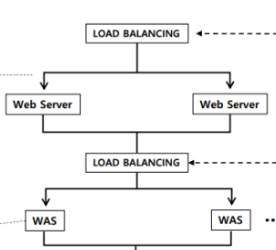
웹 서버와 웹 어플리케이션 서버 사이에는 내부 로드 밸런서(Internal LB)가 위치해 있다.
클라이언트가 웹 서버에 요청을 보내면, 내부 로드 밸런서를 통해 요청이 이중화된 웹 어플리케이션으로 전달 된다.
[02] 문제 발생
아래 두 가지 상황에서 502 에러 화면이 노출 되는 문제가 발생하였다.
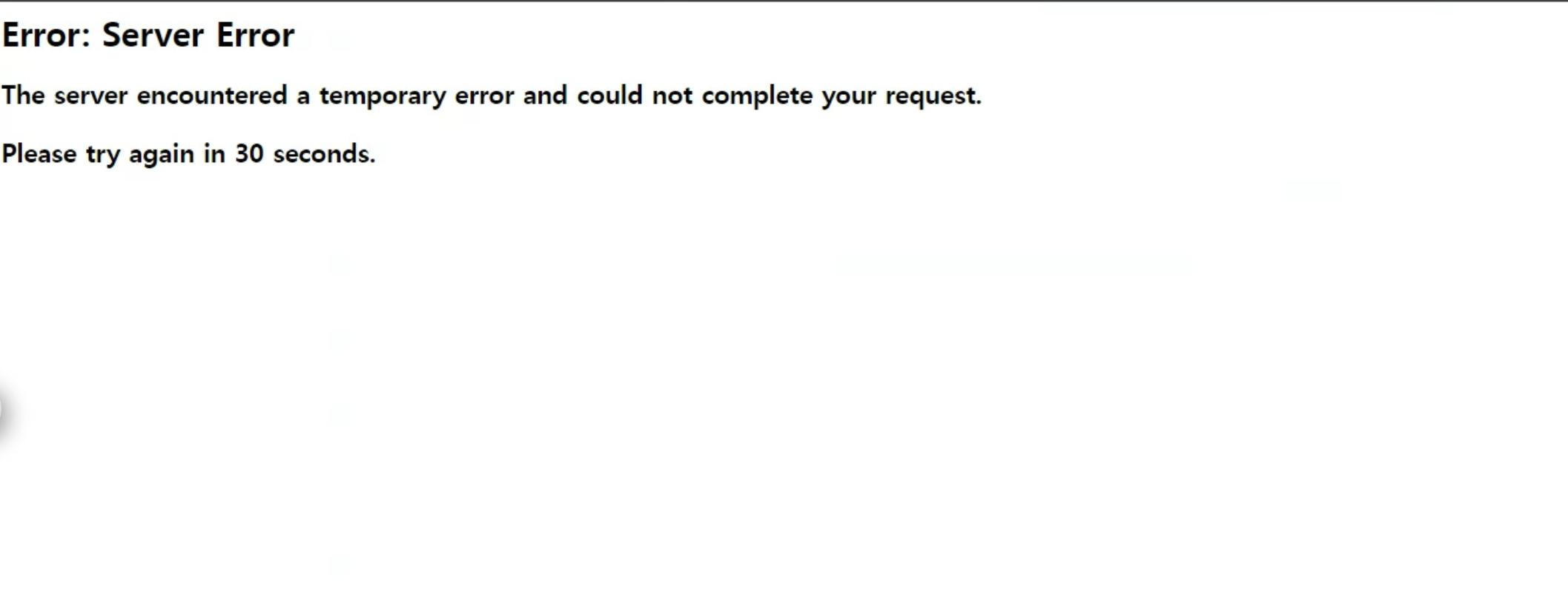
1. 운영 배포 시 웹 어플리케이션 서버(WAS)가 중단되는 경우 2. SQL 부하로 인해 WAS에서 정상적인 응답을 전달하지 못하는 경우
2번의 경우 비효율적인 SQL이 근본적인 원인이므로 별도로 대응하였다.
그러나 1번처럼 운영 배포 시 웹 서버가 다운되는 문제는 해결이 시급하였다.
[03] 원인 분석
먼저 Nginx의 access.log를 확인한 결과, 502 헬스 체크에러가 지속적으로 발생하였다.
처음에는 지속되는 헬스 체크 에러로 인해 WAS 내부 로드 밸런서 문제라고 생각하였고, 더구나 ‘WAS가 다운되어도 웹 어플리케이션이 죽는다고?’라는 생각에 더욱 GCP 로드 밸런서 쪽으로 의심이 기울었다.
다음 테스트로 원인을 확인했다.
- WAS가 다운된 상태에서 내부 로드 밸런서 상태 확인하기
WAS 가동상태에 따라 헬스체크 상태창을 정상적으로 표시되어 패스!
결과적으로 502 에러 화면은 웹 서버가 셧다운되면서 웹 로드 밸런서에서 노출시키는 화면으로 확인되었다.
첫번째 조치
다음으로 WAS와 WEB을 연결하는 부분을 분석하였다.
서버 코드를 살펴본 결과, WAS와 WEB 통신은 express의 proxy middleware를 사용하여 이루어지는 것을 확인.
코드를 분석해보니, 클라이언트가 브라우저를 통해 대시보드에 대시보드에 접근하면 구글 OAuth 인증 방식을 통해 로그인 여부를 체크하도록 되어 있었다. 사용자 트래픽이 발생하면 지속적으로 로그인에 대한 요청이 WAS 쪽으로 전달되는 것을 확인.
const express = require('express')
const { createProxyMiddleware } = require('http-proxy-middleware')
server.use(
'/proxy',
createProxyMiddleware({
target: process.env.API_HOST, // WAS 측 LB URL
secure: false,
timeout: 10000,
proxyTimeout: 10000,
pathRewrite(path) {
return path.replace('/proxy', '')
},
onProxyReq(proxyReq, req, res) {
req.session?.token &&
proxyReq.setHeader('X-AUTH-TOKEN', req.session.token)
if (req.session?.ip_addr_info) {
proxyReq.setHeader('X-Forwarded-For', req.session.ip_addr_info)
}
},
onError(err, req, res) {
res.status(500).json({ error: 'Proxy error' });
},
}),
)
axios 통신 링크 쪽에 에러 발생 시 catch 문으로 에러를 처리하도록 수정하였고, timeout 옵션을 사용하여 최대 5초까지만 커넥션을 유지하도록 설정하였다.
axios
.get(curUrl, {
params: curParams,
timeout: 5000, // 5초
})
.then(({ data }) => {
const url = data?.data?.url
res.redirect(url)
})
.catch((e)=>{
console.log(e)
res.status(500).send({ error: 'An error occurred while processing the request.' })
})
두번째 조치
두 번째 의문점은 이 정도의 구성으로 웹 서버가 죽을 수 있는지에 대한 것이었다.
시스템 오픈 후 웹 서버의 리소스를 확인하지 않았으나, PM2를 사용하여 관리되고 있어 바로 리소스 확인을 진행하였다.
pm2 monit
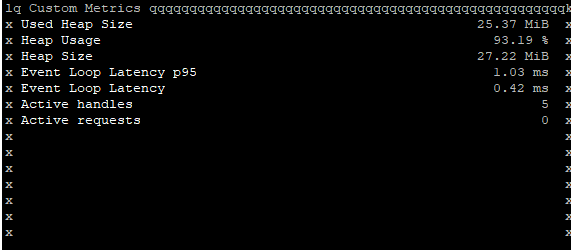
pm2의 모니터링 결과를 확인한 결과, 힙 사이즈가 부족하여 웹 서버가 다운되는 것으로 판단되었다.
프로세스 관리 라이브러리로 pm2를 사용하고 있었기 때문에 pm2 프로세스 실행 명령어에 heap 증가 아규먼트를 추가해주었다.
pm2 start $1 --node-args="--max-old-space-size=2048"
웹 서버의 힙 사이즈를 늘리는 방법을 적용하여 문제를 해결하였고 추가적인 모니터링이 필요할 듯하다.